作者:匿名 2024年9月12日 下午2:19
Vitis数据库库是一个开源的C++编写的库,主要目标受众是SQL引擎开发人员,用于把SQL执行引擎算子或者文件合并任务卸载到FPGA上进行加速。
目前,该库提供了三个级别的加速:
在模块级别,它提供了大多数常见关系数据库执行计划步骤的优化硬件实现,例如Hash Join和Agg操作。
在内核级别,可以使用“post-bitstream-programmable”的内核来映射一系列执行计划步骤,而无需为每个查询编译FPGA的binary。
软件API级别,封装了使用可编程内核进行加速的详细信息,并允许用户在Alveo卡上加速支持的数据库任务,无需异构开发知识。
GQE 包括 of “post-bitstream programmable” 的Kernel 以及对应的 software 层API.
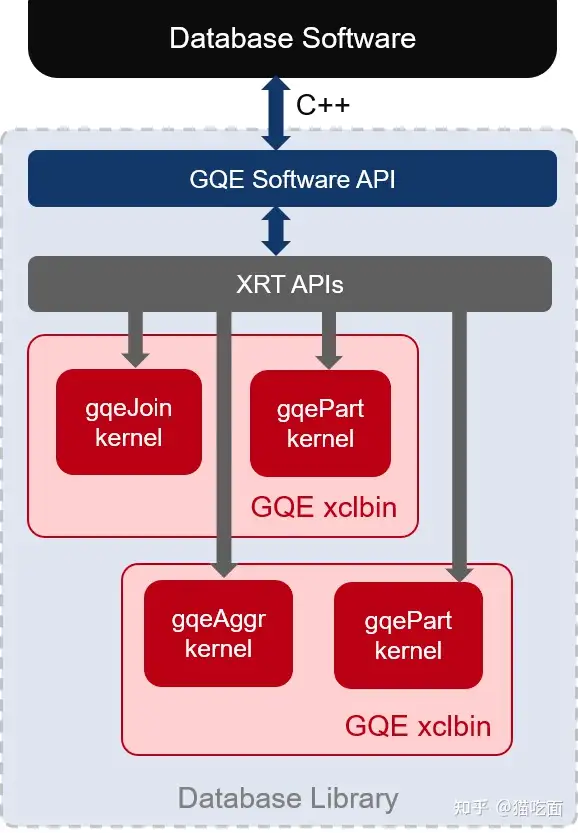
The Database Library 依赖于 HBM, 所以 high-level APIs (L2 and L3) 主要针对Alveo型号
FPGA 可以通过以下方式提高运算符性能:
通过创建customzied的pipeline来实现指令并行性。
通过同时处理多行数据来实现数据并行性。
可定制的BRAM/URAM/HBM内存层次结构,为像bloom filter和hash join这样的operator提供高带宽的内存访问。
L1 API是算子的primitve的HLS实现。如filter/聚合/bloom filter/hash join等。
L2 API 的目标用户是对HLS 和FPGA编程有一定了解,想修改kernel的开发者。
L2的API是直接运行在FPGA上的kernel,是已经编译好的执行算子的binary文件。用户通过使用L2 API就不需要每次查询重新编译binary了。
用户只需要通过提供输入配置就可以调用kernel完成特定的算子步骤。
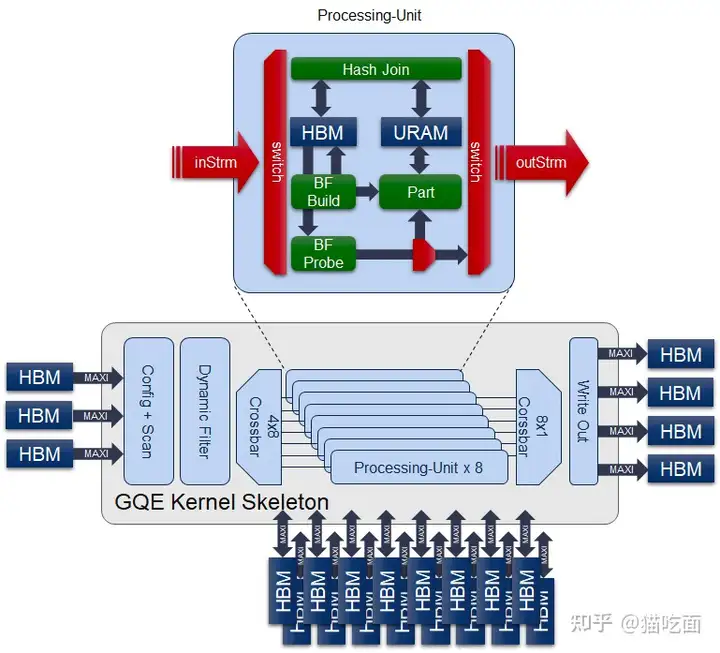
L2 APIs是多processing unit的组合,每个unit由多个stage组成。通过这种方式,kernel可以同时处理多个数据,并对同一数据应用多个操作。
L2 API用stream 和胶水逻辑把L1层的算子集合在一起,开发者可以在kernel中自定义增加算子。
增加若干预处理/后处理的逻辑,例如把数据的压缩/解压 offload到FPGA上。这样包含整个解压/算子执行/压缩都可以整合在一个pipeline上来提高系统的吞吐
单卡上可以执行多个kernel的排列组合,通过调整这个组合来实现最佳的执行计划。
3-in-1的GQE内核是多个先前发布的GQE内核(Join/Bloom Filter Probing/Build BF & Partition)的组合,包含许多“post-bitstream programmable”可编程原语。
它不仅可以单独执行哈希连接/哈希布隆过滤器/哈希分区,还可以执行哈希构建布隆过滤器+分区或布隆过滤器探测+分区的组合,以最小化中间数据传输。
为了在资源有限的U50 Alveo上实例化3合1内核以获得最佳的性价比,重构了每个处理单元(PU)以及输出数据路径,并在当前内核中废弃了bypass设计。
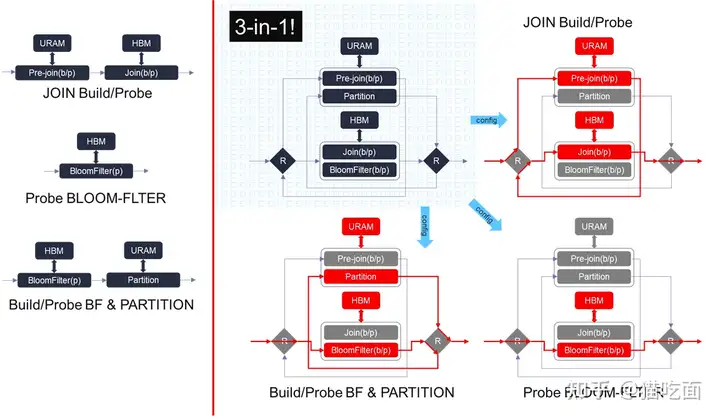
上图展示了3合1 GQE的内部结构。在3合1 GQE中实现的硬件结构可以重复使用每个处理单元中的2个AXI-Master端口和3个内部巨大的URAM缓冲区,以实现在单个U50上实现gqeJoin/gqeBloomfilter/gqePart的目标。
当使用布隆过滤器进行建立(building)和探测(probing)操作时,我们可以假设有两个表:表A和表B,它们具有以下结构:
表A:
| id | column1 |
|---|---|
| 1 | value1 |
| 2 | value2 |
| 3 | value3 |
表B:
| id | column2 |
|---|---|
| 1 | value4 |
| 2 | value5 |
| 3 | value6 |
现在,我们想要执行以下SQL查询:
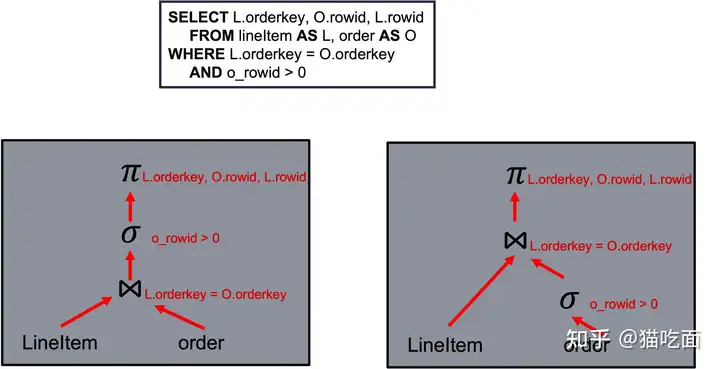
SELECT *FROM AJOIN BON A.id = B.idWHERE A.column1 = 'value1';执行计划如下:
建立布隆过滤器(building):
从表A中选择所有符合条件A.column1 = 'value1'的记录,即只选择id为1的行。
对这条记录使用哈希函数生成哈希值,并将其插入布隆过滤器中。
探测布隆过滤器(probing):
从表B中选择所有符合条件A.column1 = 'value1'的记录,即只选择id为1的行。
对这条记录使用哈希函数生成哈希值,并与布隆过滤器进行比对。
如果哈希值存在于布隆过滤器中(即id为1的记录),则将其作为候选结果。
分区(partition):
在哈希连接(hash join)之前,根据哈希值的范围对候选结果进行分区。
在这个例子中,只有一个候选结果(id为1的记录),所以只会有一个分区。
哈希连接(hash join):
对于每个分区,将表A和表B中具有相同哈希值的记录进行连接操作。
在这个例子中,会连接表A中id为1的记录和表B中id为1的记录。
通过布隆过滤器的建立和探测操作,我们可以在查询之前使用哈希函数将要匹配的记录插入布隆过滤器中,然后在探测阶段只选择与布隆过滤器匹配的记录作为候选结果。这样可以减少探测操作的数据量,提高查询的效率。分区操作可以根据哈希值的范围对候选结果进行划分,使得在哈希连接阶段可以更高效地处理数据。这些优化可以帮助加速查询的执行,并提高整体的效率。
结合L2层3-in-1的API,这个SQL的执行计划的四个步骤就可以offload到GQE上,复用了硬件资源,从而减少了算子间的数据传输。
我们需要这种可重用的硬件结构的原因是因为U50的资源限制以及不同算子中URAM和HBM的不同优先级。
JOIN建立/探测流程:需要首先在URAM中保存unique key的总数,然后将key/payload pairs保存在HBM中。
布隆过滤器建立/探测流程:需要使用HBM访问其相应的哈希表。
PARTITION流程:需要使用URAM缓冲区来缓存被partitioned的key/payload pairs,以在flush partition后的bucket时获得合理的吞吐量。
在执行布隆过滤器 probe操作+PARTITION流程时,我们不知道特定bucket中的键/有效负载对是否足够被flush出来,为了避免在分区模块之后实现重复的URAM缓冲区,我们必须安排布隆过滤器操作在分区之前,以便充分利用分区模块中的原始URAM来收集分区后的行。因此,我们需要这种可重用的硬件结构,在不同的配置下,数据沿着不同的路径进行。
Internal multi-join 支持三种Join modes: inner-join, anti-join, and semi-join.
The join process is divided into two phases: build and probe.
Build phase 把左表作为输入构建hash table, Probe phase 以右表作为输入来过滤出冲突的行。
通过多次调用表B,可以连接任意大小的表B。另一方面,通过将表A分割成多个切片并运行多次(构建+ N次探测),可以使用任意大小的表A作为左表。该内核使用三种类型的输入缓冲区,即1个内核配置缓冲区、1个元信息缓冲区、1个验证位缓冲区和3个列数据缓冲区。结果缓冲区包括1个结果数据元信息和4个输出列数据。
3合1 GQE内核支持布隆过滤器的构建和探测流程,该实现充分利用了HBM的高带宽特性,加速了查询(包括构建和探测)能力,并同时扩展了容量尽可能大。 由于布隆过滤器与3-1 GQE共享相同的hardware resources。因此,输入的key和payload pair应为64bit以及1 or 2 key column(s), 1 playoad column plus 1 validation-bit column。
GQE的partition kernel可以根据所选key column的哈希值将input table分割成partition,旨在扩展GQE join 或agg kernel可以处理的数据规模。
为了减少中间数据传输的大小,它配备了内置的dynamic filter和基于HBM的布隆过滤器。
它扫描内核配置缓冲区、元信息缓冲区和3个列的输入原始数据,并传递给内置的dynamic filter。过滤条件在内核配置缓冲区中的地址0x06到0x13中配置。
经过过滤后,每行数据将被分派到其中一个8个PU单元中计算primary key的哈希值。
基于哈希值和在配置中设置的BF的构建/探测标志,key和payload data将首先通过基于HBM的布隆过滤器,然后保存到相应的桶/分区中。一旦一个桶满了,满桶将触发一次burst write,将数据从内部URAM bucket flush到off-chip的缓冲区。
内部URAM数组中最多创建256个桶,每个桶缓冲一次突发写入,并在满时将结果刷新到offchip buffer。partition kernel的输出是3个列的output data和1个输出meta缓冲区。
The internal structure of this kernel is shown in the figure above.
和Join Kernel 相同,Agg的Kernel的data buffer有8列,一个kernel config buffer以及一个meta info buffer作为kernel的输入。
由于输出的数据类型可能会有多种,例如agg max/min/等,输出buffer会使用一个16列的buffer。
在进入hash group aggregate模块之前,将对每行中的每个元素进行评估和筛选。因此,可能会生成一些新元素,并且可能会丢弃一些行。此外,还添加了两个级联的评估模块,以支持更复杂的表达式。
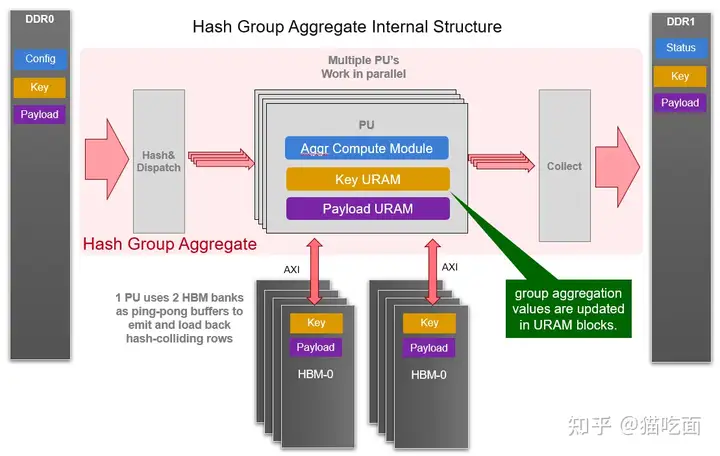
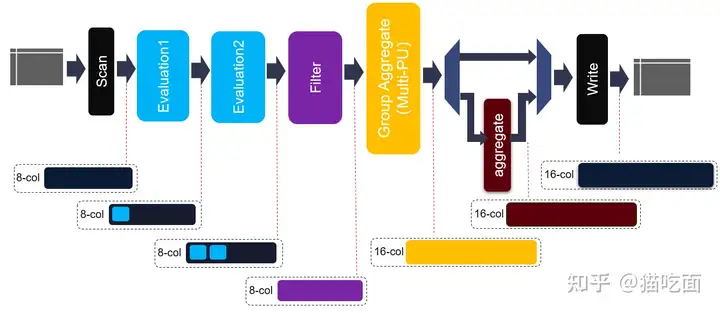
Agg Kernel的核心模块是Hash Group Agg,包含了多个可以并行执行的PU。每个PU都需要2个HBM bank作为ping-pong buffer和一些URAM内存block来缓冲聚合操作后的不同key和payload。并且会有一个inner loop被实现用于在每次iteration中消耗所有输入行。
L3 API的目标用户为仅仅想把API作为第三方共享库链接到自己项目中,然后直接调用API来在FPGA直接执行加速部分的执行计划的开发者。
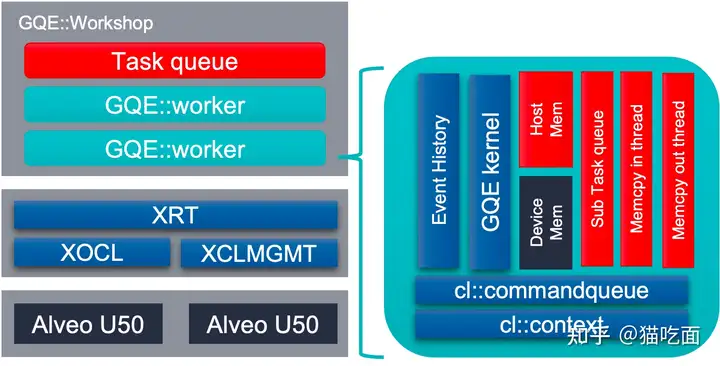
GQE的L3 API它们负责调度内核执行、数据传输和CPU数据移动,并隐藏了详细的OpenCL调用。该API提供了三个类别的软件API,包括join、bloom-filter和group-by聚合。在此版本中,Joiner和Bloomfilter已经优化以支持64位数据的输入/输出。聚合API保留了与2020.2版本相同的32位数据输入/输出。
Join有两个阶段:构建和探测。当构建表固定时,探测效率与探测表大小成线性关系。然而,当构建表变大时,探测的性能下降。在实际场景中,构建表和探测表的大小是未知的。因此,为了支持具有高效性能的不同大小的两个表的连接,L3中提供了两种解决方案:
解决方案1:直接连接(1x构建+ Nx探测),适用于构建表不太大的情况。
解决方案2:哈希分区+哈希连接,将左表和右表分区为M个分区。然后,对每个分区对执行构建+ Nx探测。
在解决方案1中,构建表的大小相对较小,因此探测阶段是高效的。
为了尽量减少数据传输和CPU数据移动的开销,probing表被水平地分成多个部分。
当构建表很大时,将输入表分区为多个分区可以保持构建+探测的高性能执行。
解决方案2包括三个顺序阶段:分区构建表O,分区探测表L,以及多次执行解决方案1。
对于每个阶段,采用流水线式任务调度。
workshop 作为L3 API对FPGA卡以及CPU-FPGA任务流的管理器,由以下三个部分组成:
Worker向量:每个Worker实例将管理一个Alveo卡和管理设备缓冲区及其主机映射固定缓冲区。它们将处理以下任务:1)将输入数据从固定内存迁移到设备内存,2)设置内核参数并调用内核,3)将元数据从设备内存迁移到固定内存,4)基于元数据将结果数据从设备内存迁移到固定内存。
1个内存复制器,从主机到固定缓冲区:具有8个线程,用于将输入内存中的数据复制到主机映射的固定缓冲区。
1个内存复制器,从固定缓冲区到主机:具有8个线程,用于将输入内存中的数据复制到主机映射的固定缓冲区。
workshop的构造函数将找到所有具有相同所需shell的卡,并使用提供的xclbin文件加载它们。构造函数完成后,它将创建与卡对应的相同数量的worker进行管理。
只有在调用释放函数时,与OpenCL相关的上下文、程序、内核和命令队列才会被释放。
工作坊支持在多个卡上执行高性能的连接操作,并支持异步输入和输出。
哈希聚合是一种聚合操作的实现方法,用于将相同键值的数据行合并为单个结果。
在哈希聚合中,首先根据聚合操作的键值对输入数据进行哈希映射,将具有相同键值的数据行分配到相应的哈希桶中。每个哈希桶中的数据行具有相同的键值。
接下来,对每个哈希桶中的数据行进行聚合操作,这个过程可以并行化。这包括计算统计值(如求和、计数、平均值等)或执行其他指定的聚合函数。
最后,将每个哈希桶的聚合结果合并为最终的聚合结果。
在L3 API中,Aggregator有以下所有解决方案:
解决方案0:哈希聚合,仅用于测试小型数据集。
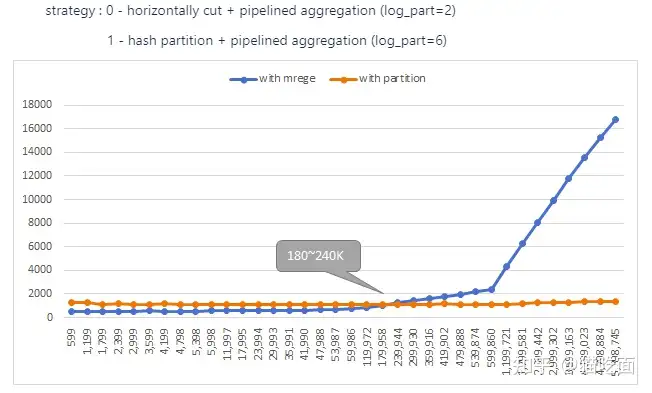
解决方案1:水平分割+pipelined哈希聚合。
解决方案2:哈希分区+pipelined哈希聚合。
在解决方案1中,将第一个输入表水平分割成多个片段,然后对每个片段进行聚合,最后合并结果。
在解决方案2中,将第一个输入表哈希分区为多个哈希分区,然后对每个分区进行聚合(最后不需要合并)。比较这两个解决方案,解决方案1引入了额外的CPU合并开销,而解决方案2增加了一个额外的kernel(哈希分区)执行时间。
总结一下,当输入表具有较高的unique key数量(超过180K-240K)时 哈希分区+哈希聚合 比解决方案1水平分割更有利。
2022.1
GQE将partition/bloom filter/Join合并为单个内核。
将这三个操作符合并为单个内核可以使它们在FPGA上共享资源。虽然这样的内核一次只能执行其中一个操作符,但它所使用的资源要比三个独立的内核少得多。通过这样的设计,可以消除为不同操作符切换xclbins的时间成本。此外,这样的设计还可以实现内核的流水线执行,并减少DMA的工作负载。这个设计针对的是 Alevo U50。U50的成本较低,但仍保留了HBM(高带宽内存)。
2.Key-Value store offloading 引入了一个新的Kernel,用于加速日志结构合并树数据库中的K-V压缩操作。
异步输入/输出:使用std::future<size_t>通知GQE L3每个输入部分的就绪状态,其值是输入部分的有效行数。它将使用std::promise<size_t>通知GQE L3的调用者每个最终结果部分的就绪状态,其值是输出部分的有效行数。异步支持将允许FPGA在部分输入数据就绪时立即开始处理。这样,FPGA不需要等待所有输入数据就绪,从而缩小了为FPGA准备数据的开销。
多卡支持:允许识别适合工作的多个Alveo卡。它将为这些卡加载相同的xclbins,并在有多个任务时调用它们,以便同时处理超过1个卡能够处理的任务。数据结构还将在显式释放之前保持固定主机缓冲区(host buffer)和设备缓冲区(device buffer)的活动状态。这将有助于节省加载xclbins/创建固定缓冲区/创建设备缓冲区的时间。
64位Join支持:现在,gqeJoin内核及其伴随的gqePart内核已扩展到64位键和有效载荷,以支持更大规模的数据。
布隆过滤器支持:gqeJoin内核现在具备执行布隆过滤器探测的模式。
GQE内核现在将每个列作为输入缓冲区,这可以极大地简化host code的数据准备工作。与一个连续的大缓冲区相比,在host端分配多个buffer会减少内存不足问题,特别是在服务器负载较重时。
L2层现在提供了命令类来生成GQE内核的配置位。开发人员不再需要深入了解bitmap表,以了解在GQE流水线中启用或禁用功能时应切换哪个或哪些位。
对L3 API的支持。它们可以根据hash对表进行分区,然后分别调用GQE内核。数据库专家可以根据表统计信息对执行进行微调,而不会干扰OpenCL执行部分。
复合排序API(compoundSort):之前提供了三个排序算法模块,而这个新API结合了insertSort和mergeSort,为芯片上排序提供了更可扩展的解决方案。当使用32bit integer key时,FPGA上一个SLR上的URAM资源可以支持扩展到2M个。
在(hashJoinV3)中更好地利用HBM带宽:在2019.2 Alveo U280 shell中,启用了ECC。因此,对HBM的子ECC大小写入变为读-修改-写,并浪费了一些带宽。此版本中的hashJoinV3已被修改为使用256bit端口,以避免此问题。
